If you can spare a few dollars, it would help a lot: PayPayl.me/Guard13007
It’s been about a year of subpar income with no benefits, keeping us alive but still in danger, and now that is gone entirely. :D

Miscellaneous Idea Storage
If you can spare a few dollars, it would help a lot: PayPayl.me/Guard13007
It’s been about a year of subpar income with no benefits, keeping us alive but still in danger, and now that is gone entirely. :D
This blog post was written in early January, 2026, and updated just before publication to correct errors and add details, mostly through footnotes. The tl;dr is that I was misled into believing a Nook would be viable eReader, but there don’t seem to be any viable eReaders anymore.
I’ve been using Google Play Books to read ebooks for years, because I haven’t found another ebook reader that uses actual pages instead of an infinite scrolling interface1. I rely on the feel of pages to help me be comfortable with stopping at specific points that aren’t chapter or scene breaks, especially in books with very long sections. For a few months, this has happened on an Amazon-branded tablet – which, to be clear, was only because it was lightweight, laying around after being given away, and could be hacked to remove a lot of Amazon’s spyware and control2.
That said, I never completely eliminated Amazon’s crapware from it, and it was dropped a few times, leading to the state of sprinkling glass dust around and being slightly difficult to read now. And it’s a tablet capable of playing videos using Grayjay and browsing the web. This is nearly unacceptable, because I refuse to lock the device due to wanting quick and easy access to my books, but it’s insecure. I have accounts on it disconnected from most of my things, but not ALL of my things. It’s dangerous.
It’s also distracting. I mentioned videos and web access because I spend more time on it watching videos than reading books. That’s not what it’s for. So I started looking up eReaders, knowing that I should be able to afford a very cheap and maximally incapable device so that it can truly be only for ebooks. Amazon is right out because they do not allow buying ebooks anymore3, 4, and they even completely blocked downloading ebooks in February 2025. Their propaganda is so effective I believed it had been temporarily suspended in 2026.
Critically, the experience of checking out a library ebook is functionally identical to downloading a copy from Amazon.
– VP of Grand Central Publishing (an imprint of Hachette) in the Internet Archive Controlled Digital Lending litigation5
Amazon also designs all their devices to constantly advertise to you and collect information about you6. It’s spyware and adware they make you pay for. To some extent, this is always unavoidable, but you can at least avoid giving more power to the largest reduction in author income7, 8, 9, 10.
The only other options seem to be Kobo and Barnes & Noble’s Nooks. I’ve used a secondhand Nook many years back, and it was perfect for the brief period of time I had it. Long-lasting battery, fast enough, only does books, and no distractions. I really appreciate e-ink displays as well for their low power consumption and encouragement to do tasks with little screen activity – like reading. That said, I try to research things before making choices, so I spent time comparing options.
Kobo devices can only be obtained through shipping or Walmart11, and there are many reasons to avoid giving them any more power. They’re also wholly unfamiliar to me, and while looking up info online revealed a lot of info on how to hack them, ideally, I’d use a device that just works instead of one I have to fix before I can use it. (I also stumbled across their parent company being claimed to be Japan’s Amazon12 in terms of invasions of privacy13, 14 and criminal malfeasance15, so I don’t exactly like that.) Oh, and they have browsers and extra features that can distract, when the whole reason I want an eReader is to have something that does nothing except read books.
I made a video reviewing my Kobo e-reader from an accessibility POV and I had to cut a whole tangent about their AI help bot as it ran too long but it’s my view they are an accessibility nightmare due to the cognitive load required to get what you want. Their one goal is to make you give up.
– Philip @disabledphil.bsky.social
Nooks have physical buttons, which make reading with them easier, and do nothing except access Barnes & Noble’s store and read books. They also don’t require any special hacks to put your books on them. Perfect fit? That’s what I thought.
After obtaining the device, the first hurdle was requiring an account and to be online to set up the device. This is nearly unacceptable, but a small price to pay when you never need to connect again to use it. I decided to ignore the yellow flag and continue. It immediately wanted to update, but as I only had the power available on the device from factory (somewhere under 30% – and you shouldn’t trust a brand new battery meter immediately either), I skipped this. It was also near closing time for the Barnes & Noble I was at, and I wanted to make sure it was usable before leaving.
I downloaded a few books from their free collections, and headed home. At home, I started copying my books onto it and charging the device. I found that most of my in-progress ebooks loaded fine, but two had errors I needed to fix with calibre. A couple of them loaded a little slow, but this didn’t seem too bad to me. I decided to try the shelves feature and organized the 79 books I’d imported and jumped to where I was in them. The second yellow flag was that the page numbers didn’t match. Some books were suddenly longer, some shorter.
I’d read that Nooks support archiving your books through their cloud service to keep track of where you are in books, annotations and highlights, and so you can free space on your device when needed (this is misleading claim, as all of these features are locked behind purchasing said books through their store, but this is not highlighted). I bought their 32 GB device so I’d have a long time before needing this, but it’s still nice to free up space when you can, so part of my loading of ebooks was loading a couple that I’d finished so that I can archive them and mark them as read. It turns out, not only can you not archive your own books, but you can’t even delete them. (I organize my ebooks through a web interface based on calibre, so I was fine deleting them.)
At this point, the battery had charged enough I was comfortable updating the device, so I went looking for how to do that. Not only is there no obvious way of doing this, but official instructions online all point to options that do not exist on the device. I figured maybe the online copies had all been updated and the stock version doesn’t have the option until it updates, which sucks, but I can deal with it once it figures out to update itself.
I continued copying in books and fixing a few more errors with my own files, until it decided on its own after a reboot to update. This update deleted my shelves and book progress. That’s a red flag for me, but I’ve been told I’m a bit too quick to judge, so I decided to push past this and try to use the product anyhow. I recreated a test shelf – unwilling to waste time organizing when I felt sure the organization would be deleted again.
I again looked for how to check for updates, and the instructions still don’t match, even though there are minor changes on the device after the update. Then, after another reboot, it automatically updated again. Automatic updates that don’t update to the latest version are another yellow flag for me. It indicates someone didn’t make the update progress reliable and consistent. (It’s not quite a yellow flag to me for updates to appear and start applying without warning, but it very nearly is one, because that’s incredibly rude and does not care for what you’re doing, or how urgently you may need to access something on a device. Imagine your phone decided to apply an update while you’re trying to pull up your medical information in an ER. That delay could kill you.)
Again, my test shelf was deleted. At this point, I discovered my book progress at least was not actually deleted, but simply hidden until I opened a book again. This is not exactly a yellow flag, but still strange behavior – the data is unchanged, so why did the interface change to show every book as never opened until I open it again? It does not instill confidence when a device randomly hides and changes important user information like this.
At some point during all this, I’d noticed that the device was only showing 5 GB available when it should be approximately 27-29 GB available depending on exactly how much Barnes & Noble rounded the listed specs and how much space the operating system uses, and I’d been looking at other users troubleshooting various issues while trying to find out how to update the device manually. I stumbled across people losing their entire libraries or all annotations and highlights after updates. This is nearly a red flag. Fluke issues just happen sometimes, but I’d already been experiencing multiple data loss events here, and saw evidence I would encounter more over time.
We’re on update 2, right? I lost my place because so much shit happened. I finally found how to check for updates, which is hidden under “About” in the settings (which is not stated in the manual or online anywhere I could find – they say it’s under a different label, though I cannot remember what right now). This update system also updates 3 components separately, the reader, the store, and the “platform” (which I assume is the actual operating system). And surprise, it needs to update again. When I checked, there were no updates available, but after another reboot as part of troubleshooting the other issues I experienced, it decided to update a 3rd time!
This 3rd update didn’t delete the test shelves I’d remade, so progress? But I was already feeling kind of sick of all this crap so I treated this suspiciously instead of as a win. I’d been noticing slower loading times after the 2nd update, and occasional complete lack of response to input, but sometimes I’m too gentle, so I gave this a pass for now – I might’ve accidentally touched the bezel or missed a button after all, it’s a small screen!
At this point, if I could replace this device with a factory update version and never go online with it or otherwise disable updates, it would still be acceptable. I’d have an efficient eReader that handles my books, and I already manage them elsewhere. The page numbering being wrong is annoying, but ultimately, I care more about reading than getting those details perfect. But you cannot set the device up without a connection and account, and it automatically downloads updates to decide when to install them later. This would still potentially be acceptable if I could make that initial connection fast enough to interrupt the download.. but there’s another problem – Barnes & Noble advertises that they made a deal with AT&T to make these devices automatically connect to any of their hotspots automatically, and it also automatically recognizes and connected to any Barnes & Noble WiFi. As a result, I’d be essentially walking around with a hand grenade ready to go off any time. If I ever accidentally enabled the wifi and happened to be near AT&T infrastructure or a Barnes & Noble, I’d instantly lose my organization and have a device that works significantly worse. No thank you. I’m not living with that threat. And who knows? Maybe they have a timeout where if you don’t connect to the internet for a long time, it logs you out and forces you to set it up online again? I’m not taking that risk.
But honestly, that was something I only thought of after finding the final red flag. I was still willing to put up with this worse performance until I discovered why it kept saying it had significantly less storage space than I paid for. Barnes & Noble decided to limit your book storage to 5 GB on all of their devices. Their store can use all of the space, but your books are only allowed a small fraction of the device. This eliminates the majority of the point of buying the device for me, and especially the point of buying the slightly more expensive version with more space on it.
I refuse to accept this level of assholery and bad design for an ebook reader.
I want to read “Agency Pricing and Bargaining: Evidence from the E-Book Market” by Babur De los Santos et. al, which is updated every so often, apparently, since I’ve found a 2021 and 2025 version. But that’s near 50 pages long, and I’m tired. So consider it further suggested reading, I guess. It’s about how pricing changes depending on negotiating positions and types of negotiations.
I was initially concerned about the use of footnotes within footnotes making it appear like I’m trying to inflate my reference count, but it really disrupted the flow of reading one of the footnotes to NOT have separate footnotes linked like that. So fuck it, if someone wants to claim I’m artificially inflating it, fight me. I referenced the things I intended to, for the reasons I wanted. If I really wanted to inflate it, I would’ve copied a bunch of them from the NYU School of Law article5.
2026-07-25: Updated to remove WordPress’s broken “Read More” link.
Yesterday, Louis Rossmann published a video about WeRecoverData, who threatened him with a lawsuit for publishing verifiable statements about their service. One of the issues he highlighted are fake business locations, where a business substitutes an actual operation with a drop off location using a third-party, but it is presented as a service location on Google Maps.
I decided to see if there are any videos of the Denver location. There aren’t. So I went there to see if it is a virtual office. After getting home, I decided to call them. Interestingly, I called after business hours, but they answered anyhow.
They stated phone data recovery prices range from $300 – $2,500, while HDD/SSD data recovery is $500 – $5,000.
In his video, Louis also highlighted how WeRecoverData claims not to publish success rates, but their website has a claimed success rate on every page. Today, he published a follow-up about how WeRecoverData has wiped the Internet Archive’s copies of its website and blocked them from archiving them in the future.
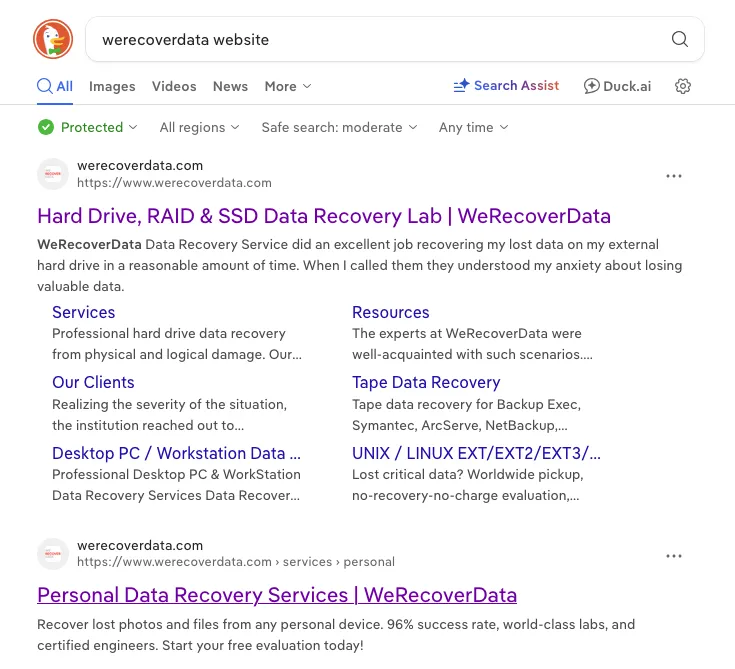
I checked just now, and they’ve removed that claim from their website. As you can see here, DuckDuckGo hasn’t yet updated its description to reflect the change, providing yet more clear evidence that this claim was factual when it was made.
I think the answer entirely depends on whether you think unfettered capitalism is suspicious, or if a company should put effort into maintaining good customer relations as well. Tesla has not violated any rules (in regards to the suspension recall / service bulletin only) as far as I can tell, but has made choices to protect their profit rather than taking responsibility for issues.
This is of course, separate from but related to Elon Musk’s support of the fascist takeover of the USA, and dismantling of federal protections and safety enforcement1. Considering Tesla vehicles kill twice as many people as the average vehicle2, that’s an understandable incentive.
I started with a vague memory of hearing something about Tesla having tires recalled in China, but dodging the same recall in the USA because of lower safety standards3. I found out about a very recent TPMS recall in the USA4 and a massive recall in China over regenerative braking modes being unselectable5, but the thing that stood out to me was China’s recall of nearly 50,000 vehicles due to suspension issues in 20206. My memory was either false, based on misinformation, or based on a misunderstanding of the TPMS issue as it was relayed to me7.

Chinese Teslas have the same suspension as American Teslas, so why is there no recall here? Apparently, in 2016, there were already enough complaints about this to encourage Tesla to put out a blog post addressing the controversy9. They state there are no problems with Model S/X suspensions and the NHTSA is not investigating them. To me, the most suspicious part of this post is their statements about making a customer sign a “Goodwill Agreement” to have repairs covered for free or reduced price, and that they claim this to be a normal part of the automotive business. It’s not.
It turns out that in addition to asking a customer to sign an NDA for 50% of the price of repairs, this may have been part of a service bulletin Tesla posted a year prior (which has been since deleted)10. This is an issue because manufacturers are not required to pay for repairs in service bulletins (unless the customer notices during a relevant warranty period), nor are they required to notify consumers. Service bulletins are not supposed to be used for things that can affect vehicle safety, but manufacturers have dodged responsibility this way before.

Tesla denied the NHTSA’s investigation (perhaps because they said “examining” and did not open a formal investigation at the time), and denied restricting customers’ ability to report to the NHTSA, even though the text of the agreement specifically requires confidentiality and denial of participation in legal proceeding. Aside from their pontificating about safety (despite having 2x the fatality rate of the national average2, and having deleted previous claims of safety), they call out an individual by name and claim he both fabricated the evidence and is responsible for a tracker of how long it would be until someone died in a Tesla, but that’s not true11.
I think it’s important to highlight that a large auto manufacturer stating an individual’s name while disparaging his publication of their shady business practices is exactly the kind of thing that leads to doxxing and death threats (or worse), especially when there is a cult of personality around its CEO. This is dangerous and unacceptable behavior when presenting to a large audience. There’s no way Tesla’s leadership doesn’t know that. In fact, I’d argue it’s the point – to stoke fear of presenting evidence.
NHTSA is examining the potential suspension issue on the Tesla Model S, and is seeking additional information from vehicle owners and the company.
NHTSA learned of Tesla’s troublesome nondisclosure agreement last month. The agency immediately informed Tesla that any language implying that consumers should not contact the agency regarding safety concerns is unacceptable, and NHTSA expects Tesla to eliminate any such language. Tesla representatives told NHTSA that it was not their intention to dissuade consumers from contacting the agency. NHTSA always encourages vehicle owners concerned about potential safety defects to contact the agency by filing a vehicle safety complaint at SaferCar.gov.
– NHTSA Communications Director Brian Thomas 10
The behavior is even stranger, as the blog post ends with not-quite-accusations of market manipulation and accusations of targeted fraud. Elon Musk tweeted, “Of greater concern: 37 of 40 suspension complaints to NHTSA were fraudulent, i.e. false location or vehicle identification numbers were used”12 and this was appended to the blog post as an “update”. However, he does actually appear to be correct about this not being a safety issue13.
Back to the suspension recall. Tesla is required to notify the NHTSA when a recall is issued in a foreign country to help prevent repeats of Ford’s irresponsible behavior killing hundreds of people in the 1990’s14. In their letter, Tesla blames Chinese drivers (which seems to be their default strategy15):
Tesla has not determined that a defect exists in either the Front Suspension Aft Link or the Rear Suspension Upper Link and believes the root cause of the issue is driver abuse, including that driver usage and expectation for damageability is uniquely severe in the China market. 16
This may be the core argument for why Tesla did not issue a recall in the USA. Tesla doesn’t want the liability. They previously issued a service bulletin for the same issue in the USA17, but it only specified a quarter of affected vehicles13. Tesla claimed extremely low actual failure rates:
The occurrence of such failures in China (approx. 0.1%) and elsewhere (less than 0.05%) remains exceedingly rare […] 16
When the NHTSA did their investigation18, they found 426 of 74,918 vehicles had experienced failure (0.57%). This is 5x more than the number of failures China used to declare a recall19. This is where the difference in how recalls are done comes into play. China took damage occurring to a component that is safety-relevant as reason to recall20, while the USA only makes recalls when there is evidence of immediate danger.
I think major components of a vehicle wearing out this fast should be recall-worthy regardless of safety impact, especially when service bulletins – despite the name including a word that literally means public notice or announcement – do not require notifying affected people. Another critical difference is that recalls must be paid for by the manufacturer, while service bulletins only have that requirement while in warranty – and only if the owner knows about it.
Thankfully, they are at least correct in that this failure does not appear to present a major safety risk, as only one injury was caused by the affected vehicles failing13. The failures tend to occur at low speeds, reducing the likelihood of harm.
I was comparing a 2014 GM recall21 to the preliminary investigation letter requiring Tesla to provide documents about suspension problems22, and I couldn’t help but notice the massive difference in how utterly dense the legalese used to define what a document is. Again, since Tesla has a history of misleading everyone, it made me curious if they are the reason for this difference, or if this difference is only in letters sent to Tesla – since they have had so many investigations and recalls.
“Document(s)” is used in the broadest sense of the word under Rule 34 of the Federal Rules of Civil Procedure, and includes all original written, printed, typed, recorded, or graphic matter whatsoever, however produced or reproduced, of every kind, nature, and description, and all non-identical copies of both sides thereof, including, but not limited to, papers, letters, memoranda, correspondence, electronic communications (existing in hard copy and/or in electronic storage), invoices, contracts, agreements, manuals, publications, photographs of all types, and all mechanical, magnetic, and electronic records or recordings of any kind. Any document, record, graph, chart, film or photograph originally produced in color must be provided in color. Furnish all documents whether verified by the manufacturer or not. If a document is not in the English language, provide both the original document and an English translation of the document. 21
I looked into the mentioned Rule 34 of the Federal Rules of Civil Procedure, which indicates a history of changes and attempts to circumvent required presentation by quibbling over what “document” means. Even the 2015 amendment may not always be specific enough, I’m guessing, which is why they include their own definition instead of relying on this.
Document: “Document(s)” is used in the broadest sense of the word and shall mean all original written, printed, typed, recorded, or graphic matter whatsoever, however produced or reproduced, of every kind, nature, and description, and all non-identical copies of both sides thereof, including, but not limited to, papers, letters, memoranda, correspondence, communications, electronic mail (e-mail) messages (existing in hard copy and/or in electronic storage), faxes, mailgrams, telegrams, cables, telex messages, notes, annotations, working papers, drafts, minutes, records, audio and video recordings, data, databases, other information bases, summaries, charts, tables, graphics, other visual displays, photographs, statements, interviews, opinions, reports, newspaper articles, studies, analyses, evaluations, interpretations, contracts, agreements, jottings, agendas, bulletins, notices, announcements, instructions, blueprints, drawings, as-builts, changes, manuals, publications, work schedules, journals, statistical data, desk, portable and computer calendars, appointment books, diaries, travel reports, lists, tabulations, computer printouts, data processing program libraries, data processing inputs and outputs, microfilms, microfiches, statements for services, resolutions, financial statements, governmental records, business records, personnel records, work orders, pleadings, discovery in any form, affidavits, motions, responses to discovery, all transcripts, administrative filings and all mechanical, magnetic, photographic and electronic records or recordings of any kind, including any storage media associated with computers, including, but not limited to, information on hard drives, floppy disks, backup tapes, and zip drives, electronic communications, including but not limited to, the Internet and shall include any drafts or revisions pertaining to any of the foregoing, all other things similar to any of the foregoing, however denominated by Tesla, any other data compilations from which information can be obtained, translated if necessary, into a usable form and any other documents. For purposes of this request, any document which contains any note, comment, addition, deletion, insertion, annotation, or otherwise comprises a non-identical copy of another document shall be treated as a separate document subject to production. In all cases where original and any non-identical copies are not available, “document(s)” also means any identical copies of the original and all non-identical copies thereof. Any document, record, graph, chart, film or photograph originally produced in color must be provided in color. Furnish all documents whether verified by Tesla or not. If a document is not in the English language, provide both the original document and an English translation of the document. 22
I can not answer whether or not this is influenced by Tesla. I have not been able to find anything discussing the change in wording, but I have compared several different NHTSA letters to try to determine when this change was made. INIM-PE11011-46062 (2011), INIM-PE15025-62339 (2015), INIM-PE16007-64338 (2016), INIM-PE18008-73938 (2018), INIS-PE20003-78174P1 (2020), and INIM-PE20016-82633P (2021) all use nearly the same definition, indicating it was used inconsistently in the past, though it seems more consistent more recently.
It seems more like it was a definition someone put together a long time ago to try to deal with all the drama over Rule 34, but it didn’t spread to wider usage until later, and it was just coincidence that I encountered a drastic difference while looking into this. I figured it was worth pointing out though, just to show how things can be inconsistent and not every signal is an indication of malice. I also think the journey to find out information can be just as interesting as the information itself, which is kind of the whole point of writing this.
I got curious about Tesla’s history of denying fault with issues their vehicles have, their history of recalls, and Elon’s rage against recalls being appropriately named after learning that Tesla has the worst safety record of any vehicle manufacturer that sells to the North American market. And this is the result of spending frankly too many hours looking at information related (and unrelated) to that.
This may contain errors, but I at least know the numbers are correct based on the CNBC article6. (Warning: Due to WordPress not handling blockquotes correctly, the “blocks” editor failing to copy quotes correctly, and the WYSIWYG editor not displaying correctly, the following section may have errors.)
Tesla Motors (Beijing) Co., Ltd. recalls some imported Model S and Model X electric vehicles
Published: 2020-10-23 13:33
Source: Quality Development Bureau—
Tesla Motors (Beijing) Co., Ltd., in accordance with the Regulations on the Administration of Defective Automobile Product Recalls and the Implementation Measures for the Regulations on the Administration of Defective Automobile Product Recalls, has filed a recall plan with China’s State Administration for Market Regulation (SAMR). Effective immediately, the company is recalling certain imported Model S and Model X electric vehicles.
Details are as follows:
(1)
Certain imported Model S and Model X vehicles manufactured between September 17, 2013 and August 16, 2017 are being recalled, totaling 29,193 vehicles.
For some vehicles within the scope of this recall, after experiencing a relatively large external impact, the rear suspension fore link ball-joint bolts may develop initial cracks. Continued driving may cause the cracks to expand and eventually result in fracture of the ball-joint bolts. In extreme cases, the suspension link may detach from the steering knuckle, affecting vehicle handling, increasing the risk of an accident, and creating a safety hazard.
Tesla Motors (Beijing) Co., Ltd. will replace the improved left and right rear suspension fore links free of charge to eliminate the safety hazard.
(2)
Certain imported Model S vehicles manufactured between September 17, 2013 and January 15, 2018 are being recalled, totaling 19,249 vehicles.
For some vehicles within the scope of this recall, after experiencing a relatively large external impact, the rear suspension upper link may deform. Continued driving may further weaken the component, and in extreme cases it may fracture, affecting vehicle handling, increasing the risk of an accident, and creating a safety hazard.
Tesla Motors (Beijing) Co., Ltd. will replace the improved left and right rear suspension upper links free of charge to eliminate the safety hazard.
Emergency handling measures
Before recall repairs are completed, vehicle owners are advised to drive cautiously and contact a service center for inspection as soon as the recall begins.
Among the recalled vehicles:
- 18,608 vehicles require replacement of both the rear suspension fore links and upper links.
- 10,585 vehicles require only replacement of the rear suspension fore links.
- 641 vehicles require only replacement of the rear suspension upper links.
This recall was carried out under defect investigation by China’s State Administration for Market Regulation. Under the influence of the investigation, Tesla Motors (Beijing) Co., Ltd. decided to adopt the recall measures to eliminate the safety hazards.
Tesla Motors (Beijing) Co., Ltd. will notify relevant users by registered mail, email, etc. Tesla service centers will proactively contact affected owners to arrange recall repairs.
Users may call Tesla customer service at 400-910-0707 for consultation. They may also visit:
- dpac.samr.gov.cn
- www.recall.org.cn
or follow the WeChat public account “SAMRDPAC” for more information and to report defect clues.
Since there is an effort to delegitimize software recalls, I feel it is important to preserve a copy of SAMR’s (State Administration for Market Regulation) statement about it:
This recall was carried out when the State Administration for Market Regulation initiated a defect investigation. Affected by the investigation, Tesla Motors (Beijing) Co., Ltd. and Tesla (Shanghai) Co., Ltd. plan to use the vehicle remote upgrade (OTA) technology to push newly developed functions for vehicles within the scope of the recall, so as to reduce the number of cases caused by long-term deep-dive problems. Depressing the accelerator pedal leads to a collision risk caused by excessive speed. Features include: (1) on vehicles that do not have a regenerative braking intensity selection, provide an option to allow the driver to select the regenerative braking intensity; (2) adjust the factory default state of the vehicle regenerative braking strategy; (3) A reminder is issued when the driver depresses the accelerator pedal deeply for a long time. 5
This is only slightly related, but I’m always amused by examples of subtle misinformation and examples of where suspicion should come in, so I’ll point out this forum post and how its writer thinks that the USA’s safety standards are more strict than Euro NCAP. That’s just not true, and hasn’t been for ..decades? Maybe only one decade. I’m not actually sure. I only started noticing the difference half a decade ago myself.
“Musk wants to run the Department of Transportation,” said Missy Cummings, a former senior safety adviser at the National Highway Traffic Safety Administration. “I’ve lost count of the number of investigations that are underway with Tesla. They will all be gone.” 1
While a lot of effort has gone into protecting art from use in training data (Mist, Glaze1, Nightshade2), it seems like this effort is mostly wasted because similar or less effort can be used to remove that protection. Thus, the only protection possible must be social.
My primary takeaway is that protection of art from image generation is fundamentally based on adding noise to images, and that by adding noise to images, this protection can be stripped away. Visual patterns are not about small details, so modifying small details is more of an annoyance and compute being wasted on both sides rather than useful action.
Artists are necessarily at a disadvantage since they have to act first (i.e., once someone downloads protected art, the protection can no longer be changed). To be effective, protective tools face the challenging task of creating perturbations that transfer to any finetuning technique, even ones chosen adaptively in the future. To illustrate this point, updated versions of Mist (Liang et al., 2023) and Glaze (Shan et al., 2023a) were released after the conclusion of our study, and yet we found these updated versions to be similarly ineffective against our methods. We thus caution that adversarial machine learning techniques will not be able to reliably protect artists from generative style mimicry, and urge the development of alternative measures to protect artists. 3
This statement is slightly undermined by the next line:
We disclosed our results to the affected protection tools prior to publication. In response, Glaze released a new version 2.1 that protects against the specific attacks we describe here. 3
I was also a little concerned by “We make the conservative assumption that all the artist’s images available online are protected.” because I think this is untrue. However, it’s probably irrelevant. While I initially assumed the study’s choice to use historical and contemporary artists would bias their results towards claiming protections are ineffective due to higher representation of historical artists in datasets, they indicated little difference between these groups. The bias introduced by preexisting art seems to have little effect.
Adding and removing noise didn’t noticeably impact perceived quality.3
The protections offered by Glaze, Mist, and Anti-DreamBooth4 are more effective for artists that are not easily mimicked by generative models. While this is obvious, it allows for easy cherry-picking to claim effectiveness of protections, or cherry-picking to argue against their effectiveness (which is why I point it out).
GLEAN5 is a model designed to bypass Glaze that is very successful, at least in its original testing.
As Glaze is a security measure to assist artists, a tool built to ”break” Glaze raises serious ethical questions. We have reached out to the Glaze team regarding GLEAN on multiple occasions, but have received no response. As such, the codebase of GLEAN will not be published until responses from the Glaze team are received.
Glaze is closed source because its authors presume that makes it more secure. 6 It also was developed using copyright infringement violating the GPL license of DiffusionBee. 7
I started this note after seeing a claim that Glaze is not broken because no one has provided evidence on bsky, and then reading the first study I found. I mistakenly searched for a Conclusions section, when they used Main Findings as the heading instead. I then looked at some of the details of how the study was performed and didn’t get a good sense of what was being claimed, so I read the whole thing later and posted my thoughts while reading it, which inspired me to copy them here.
Ironically, during the process of writing this and researching more info, I was blocked by that person, so the post has been censored of its context and hidden from anyone who might meaningfully need to be informed about these issues. 👍
(This blog post also exists in my shared notes.)
I just learned the FBI has stopped just putting trans women on lists and threatening them (and companies associated with healthcare) and has started following them (and invading homes) and is about to open up terrorism cases against activists in order to fabricate the narrative that all trans people are terrorists to back up their threats against all gender affirming healthcare and disappear even more people than have already been disappeared. I knew it was coming, I was just hoping it was coming slow enough that it wouldn’t arrive. But now it seems clear things are going to get a lot worse in the next few years before we have any chance of it getting better.
It feels hopeless to try to do anything, because there’s nothing I can do. And while I’m not a public figure, and thus much lower on the lists, I’m still there. Just because I’m last in line to be targeted doesn’t make it any better.
And unfortunately I was doing some reading and stumbled across some other really blatantly evil stuff being done by the federal government so I was already feeling rather depressed and trying to move on and ignore it because I can’t do anything about it and it is only causing me more harm to stress about it.
It’s also deeply upsetting because it’s the kind of thing most people don’t believe is happening, even if you clearly demonstrate evidence. So there’s not much push back. I’m being demonized just for existing, just like so many other people, and it’s just a small part of a much bigger plan to continue regressing on all human rights issues.
And this is after similar efforts stripped me of access to healthcare and even before that, I was arbitrarily denied most of what I need. So it’s not like I was getting anything I deserve anyhow. But now I’ll also be killed for needing it. Someday.
A year ago, I was talking to my partner about how we probably should leave the country because it’s only a matter of time before we are targeted, and it’ll be too late to leave well before that happens. Shortly after, trans people were banned from leaving the country. It’s already been too late for most of a year.
I dunno if you heard about that. It’s old news at this point, but they just stopped issuing passports for trans people. And they target trans people who already have one to make it more difficult to leave for any reason.
I think the most upsetting part is how it’s cruelty for no benefit. These efforts only extend harm to a broad range of people by targeting a minority. There is not a single shred of benefit for anyone. Not even the rich and powerful, because the economic harm does more to them than any consolidation of power assists them. :/
Ostensibly, the point is that trans people are more likely to advocate for positive change, because just being trans makes someone much more likely to recognize how many systems in place don’t actually benefit the majority. And they want to stop progress. But it doesn’t even really achieve that goal because it just highlights how bad things are.